
这一节讲述三种时间复杂度是O(n)的排序算法:桶排序、技术排序、基数排序。因为这些排序算法的时间复杂度是线性的,所以又叫作线性排序(Linear sort)。之所以能做到线性的时间复杂度,主要原因是,这三个算法是非基于比较的排序算法,都不涉及元素之间的比较操作。
桶排序(Bucket Sort)
桶排序,顾名思义,会用到“桶”,核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

如果要排序的数据有 n 个,我们把它们均匀地划分到 m 个桶内,每个桶里就有 k=n/m 个元素。每个桶内部使用快速排序,时间复杂度为 O(k logk)。m 个桶排序的时间复杂度就是 O(m k logk),因为 k=n/m,所以整个桶排序的时间复杂度就是 O(nlog(n/m))。当桶的个数 m 接近数据个数 n 时,log(n/m) 就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。
桶排序看起来很优秀,但它依然不能代替之前的排序算法。实际上,桶排序对要排序数据的要求是非常苛刻的。
首先,要排序的数据需要很容易就能划分成 m 个桶,并且,桶与桶之间有着天然的大小顺序。这样每个桶内的数据都排序完之后,桶与桶之间的数据不需要再进行排序。
其次,数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为 O(nlogn) 的排序算法了。
桶排序比较适合用在外部排序中。所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中。
比如说我们有 10GB 的订单数据,我们希望按订单金额(假设金额都是正整数)进行排序,但是我们的内存有限,只有几百 MB,没办法一次性把 10GB 的数据都加载到内存中。这个时候该怎么办呢?
现在我来讲一下,如何借助桶排序的处理思想来解决这个问题。
我们可以先扫描一遍文件,看订单金额所处的数据范围。假设经过扫描之后我们得到,订单金额最小是 1 元,最大是 10 万元。我们将所有订单根据金额划分到 100 个桶里,第一个桶我们存储金额在 1 元到 1000 元之内的订单,第二桶存储金额在 1001 元到 2000 元之内的订单,以此类推。每一个桶对应一个文件,并且按照金额范围的大小顺序编号命名(00,01,02…99)。
理想的情况下,如果订单金额在 1 到 10 万之间均匀分布,那订单会被均匀划分到 100 个文件中,每个小文件中存储大约 100MB 的订单数据,我们就可以将这 100 个小文件依次放到内存中,用快排来排序。等所有文件都排好序之后,我们只需要按照文件编号,从小到大依次读取每个小文件中的订单数据,并将其写入到一个文件中,那这个文件中存储的就是按照金额从小到大排序的订单数据了。
不过,你可能也发现了,订单按照金额在 1 元到 10 万元之间并不一定是均匀分布的 ,所以 10GB 订单数据是无法均匀地被划分到 100 个文件中的。有可能某个金额区间的数据特别多,划分之后对应的文件就会很大,没法一次性读入内存。这又该怎么办呢?
针对这些划分之后还是比较大的文件,我们可以继续划分,比如,订单金额在 1 元到 1000 元之间的比较多,我们就将这个区间继续划分为 10 个小区间,1 元到 100 元,101 元到 200 元,201 元到 300 元…901 元到 1000 元。如果划分之后,101 元到 200 元之间的订单还是太多,无法一次性读入内存,那就继续再划分,直到所有的文件都能读入内存为止。
计数排序(Counting Sort)
计数排序其实是桶排序的一种特殊情况。当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
我们都经历过高考,高考查分数系统你还记得吗?我们查分数的时候,系统会显示我们的成绩以及所在省的排名。如果你所在的省有 50 万考生,如何通过成绩快速排序得出名次呢?
考生的满分是 900 分,最小是 0 分,这个数据的范围很小,所以我们可以分成 901 个桶,对应分数从 0 分到 900 分。根据考生的成绩,我们将这 50 万考生划分到这 901 个桶里。桶内的数据都是分数相同的考生,所以并不需要再进行排序。我们只需要依次扫描每个桶,将桶内的考生依次输出到一个数组中,就实现了 50 万考生的排序。因为只涉及扫描遍历操作,所以时间复杂度是 O(n)。
计数排序的算法思想就是这么简单,跟桶排序非常类似,只是桶的大小粒度不一样。不过,为什么这个排序算法叫“计数”排序呢?“计数”的含义来自哪里呢?
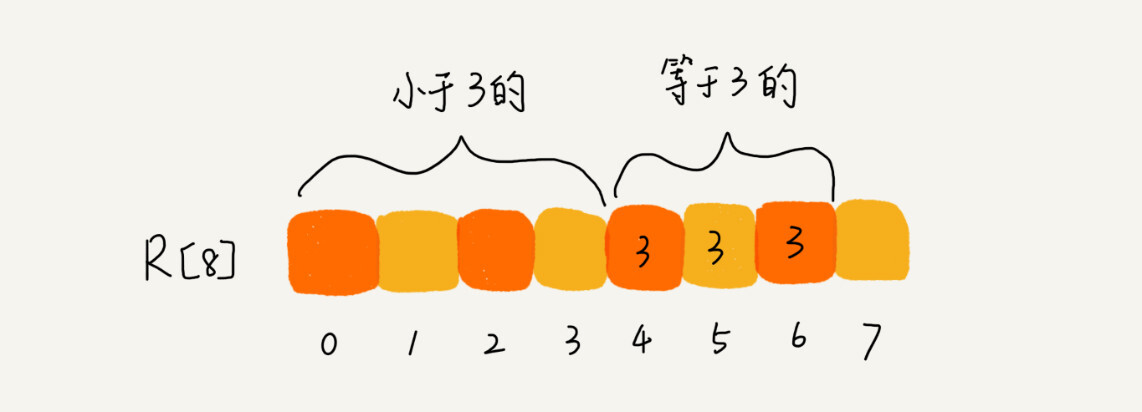
想弄明白这个问题,我们就要来看计数排序算法的实现方法。我还拿考生那个例子来解释。为了方便说明,我对数据规模做了简化。假设只有 8 个考生,分数在 0 到 5 分之间。这 8 个考生的成绩我们放在一个数组 A[8]中,它们分别是:2,5,3,0,2,3,0,3。
考生的成绩从 0 到 5 分,我们使用大小为 6 的数组 C[6]表示桶,其中下标对应分数。不过,C[6]内存储的并不是考生,而是对应的考生个数。像我刚刚举的那个例子,我们只需要遍历一遍考生分数,就可以得到 C[6]的值。
从图中可以看出,分数为 3 分的考生有 3 个,小于 3 分的考生有 4 个,所以,成绩为 3 分的考生在排序之后的有序数组 R[8]中,会保存下标 4,5,6 的位置。
那我们如何快速计算出,每个分数的考生在有序数组中对应的存储位置呢?这个处理方法非常巧妙,很不容易想到。
思路是这样的:我们对 C[6]数组顺序求和,C[6]存储的数据就变成了下面这样子。C[k]里存储小于等于分数 k 的考生个数。
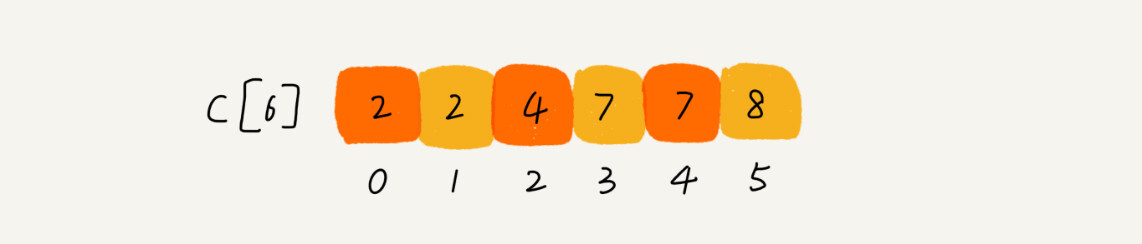
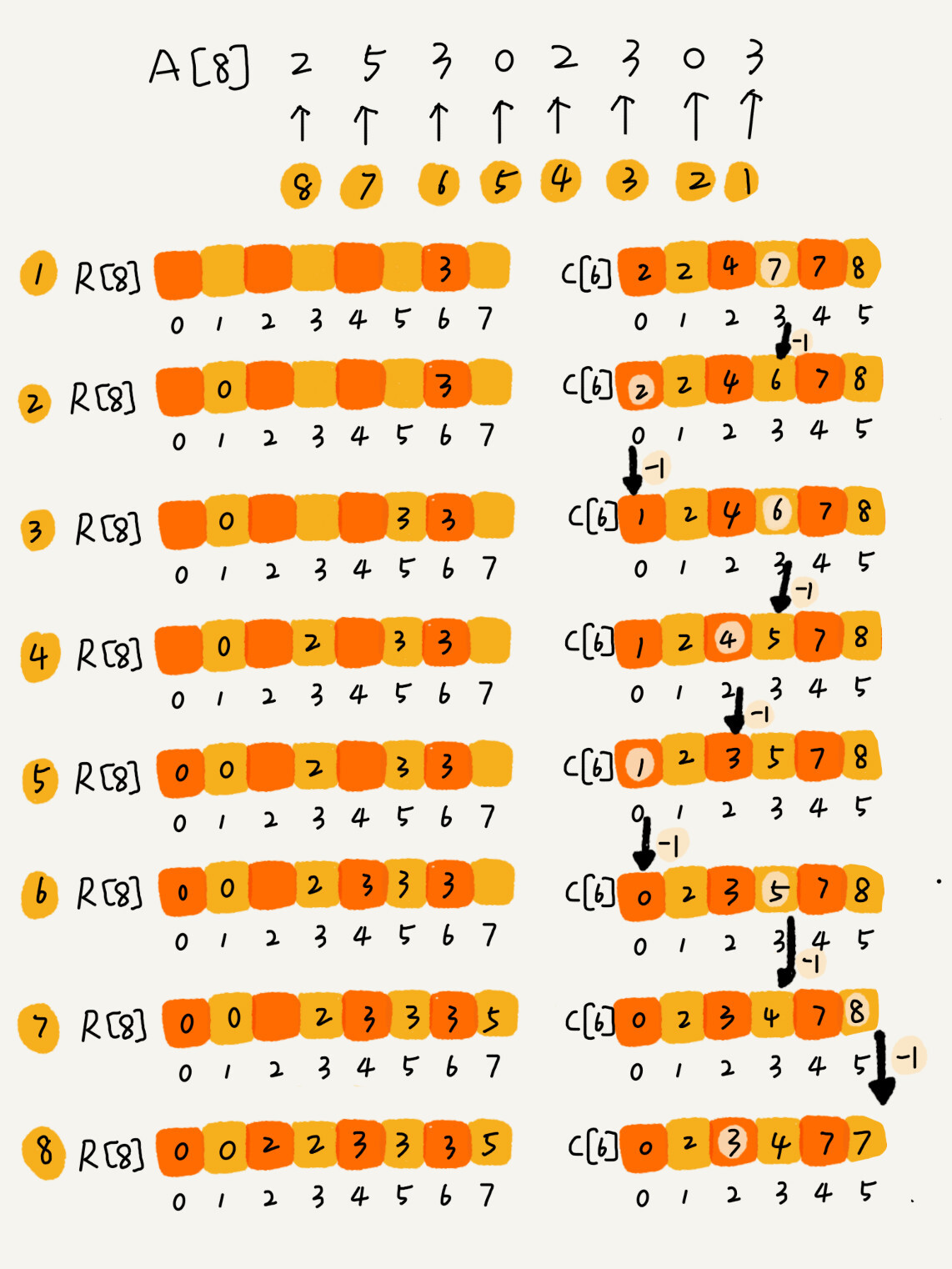
我们从后到前依次扫描数组 A。比如,当扫描到 3 时,我们可以从数组 C 中取出下标为 3 的值 7,也就是说,到目前为止,包括自己在内,分数小于等于 3 的考生有 7 个,也就是说 3 是数组 R 中的第 7 个元素(也就是数组 R 中下标为 6 的位置)。当 3 放入到数组 R 中后,小于等于 3 的元素就只剩下了 6 个了,所以相应的 C[3]要减 1,变成 6。
以此类推,当我们扫描到第 2 个分数为 3 的考生的时候,就会把它放入数组 R 中的第 6 个元素的位置(也就是下标为 5 的位置)。当我们扫描完整个数组 A 后,数组 R 内的数据就是按照分数从小到大有序排列的了。
下面是代码:
// 计数排序,a是数组,n是数组大小。假设数组中存储的都是非负整数。
public void countingSort(int[] a, int n) {
if (n <= 1) return;
// 查找数组中数据的范围
int max = a[0];
for (int i = 1; i < n; ++i) {
if (max < a[i]) {
max = a[i];
}
}
int[] c = new int[max + 1]; // 申请一个计数数组c,下标大小[0,max]
for (int i = 0; i <= max; ++i) {
c[i] = 0;
}
// 计算每个元素的个数,放入c中
for (int i = 0; i < n; ++i) {
c[a[i]]++;
}
// 依次累加
for (int i = 1; i <= max; ++i) {
c[i] = c[i-1] + c[i];
}
// 临时数组r,存储排序之后的结果
int[] r = new int[n];
// 计算排序的关键步骤,有点难理解
for (int i = n - 1; i >= 0; --i) {
int index = c[a[i]]-1;
r[index] = a[i];
c[a[i]]--;
}
// 将结果拷贝给a数组
for (int i = 0; i < n; ++i) {
a[i] = r[i];
}
}这种利用另外一个数组来计数的实现方式是不是很巧妙呢?这也是为什么这种排序算法叫计数排序的原因。
计数排序只能用在数据范围不大的场景中,如果数据范围 k 比要排序的数据 n 大很多,就不适合用计数排序了。而且,计数排序只能给非负整数排序,如果要排序的数据是其他类型的,要将其在不改变相对大小的情况下,转化为非负整数。
比如,还是拿考生这个例子。如果考生成绩精确到小数后一位,我们就需要将所有的分数都先乘以 10,转化成整数,然后再放到 9010 个桶内。再比如,如果要排序的数据中有负数,数据的范围是[-1000, 1000],那我们就需要先对每个数据都加 1000,转化成非负整数。
基数排序(Radix Sort)
再来看这样一个排序问题。假设我们有 10 万个手机号码,希望将这 10 万个手机号码从小到大排序,你有什么比较快速的排序方法呢?
之前讲的快排,时间复杂度可以做到 O(nlogn),还有更高效的排序算法吗?桶排序、计数排序能派上用场吗?手机号码有 11 位,范围太大,显然不适合用这两种排序算法。针对这个排序问题,有没有时间复杂度是 O(n) 的算法呢?者流可以用一种新的排序算法,基数排序。
刚刚这个问题里有这样的规律:假设要比较两个手机号码 a,b 的大小,如果在前面几位中,a 手机号码已经比 b 手机号码大了,那后面的几位就不用看了。
借助稳定排序算法,这里有一个巧妙的实现思路。先按照最后一位来排序手机号码,然后,再按照倒数第二位重新排序,以此类推,最后按照第一位重新排序。经过 11 次排序之后,手机号码就都有序了。
这里用字符串排序举例
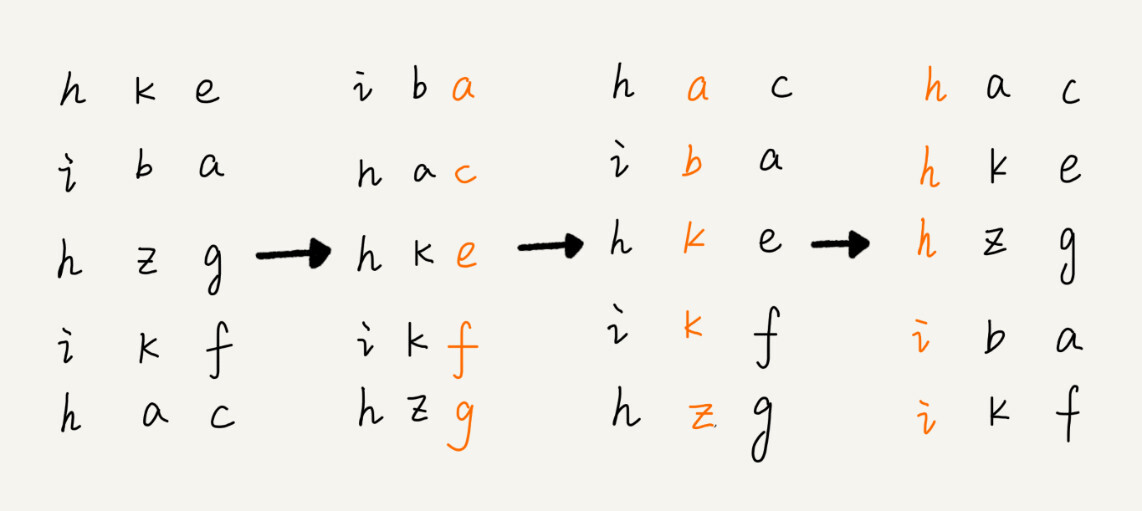
注意,这里按照每位来排序的排序算法要是稳定的,否则这个实现思路就是不正确的。因为如果是非稳定排序算法,那最后一次排序只会考虑最高位的大小顺序,完全不管其他位的大小关系,那么低位的排序就完全没有意义了。
根据每一位来排序,我们可以用刚讲过的桶排序或者计数排序,它们的时间复杂度可以做到 O(n)。如果要排序的数据有 k 位,那我们就需要 k 次桶排序或者计数排序,总的时间复杂度是 O(k*n)。当 k 不大的时候,比如手机号码排序的例子,k 最大就是 11,所以基数排序的时间复杂度就近似于 O(n)。
实际上,有时候要排序的数据并不都是等长的,比如我们排序牛津字典中的 20 万个英文单词,最短的只有 1 个字母,最长的我特意去查了下,有 45 个字母,中文翻译是尘肺病。对于这种不等长的数据,基数排序还适用吗?
实际上,可以把所有的单词补齐到相同长度,位数不够的可以在后面补“0”,因为根据ASCII 值,所有字母都大于“0”,所以补“0”不会影响到原有的大小顺序。这样就可以继续用基数排序了。
总结一下,基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果 a 数据的高位比 b 数据大,那剩下的低位就不用比较了。除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到 O(n) 了。


