
上一节中我们掌握了一些常见的复杂度,如O(1)、O(logn)、O(n)、O(nlogn)。下面我们继续四个复杂度分析方面的知识点:最好情况时间复杂度(best case time complexity)、最坏情况时间复杂度(worst case time complexity)、平均情况时间复杂度(average case time complexity)、均摊时间复杂度(amortized time complexity)
最好、最坏情况时间复杂度
// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) pos = i;
}
return pos;
}从上面的代码可以很轻易的看出时间复杂度为O(n),但是这段代码不够高效,下面这段代码是优化之后的
// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}当我们优化完代码之后,时间复杂度就不再是O(n)了。
因为x可能处于数组的任意位置。如果数组中的第一个位置就是x,那么时间复杂度就是O(1);如果数组中不存在x,那么我们就需要把整个数组都循环一次,时间复杂度就是o(n)。所以,不同情况下的时间复杂度是不一样的。
为了表示这种情况,我们引入了三个概念:最好情况时间复杂度、最坏情况时间复杂度和平均情况时间复杂度
平均时间复杂度
最好情况时间复杂度和最坏情况时间复杂度对应的都是极端情况下的代码复杂度,发生的概率并不大。为了更好的表示平均情况下的复杂度,我们需要引入另外一个概念:平均情况时间复杂度
上一段代码中,我们要查找x的位置,有n+1种情况:在数组的0~n-1位置中和不在数组中。我们把每种情况下,查找需要遍历的元素个数累加起来,除以n+1,就可以得到需要遍历的元素个数的平均值
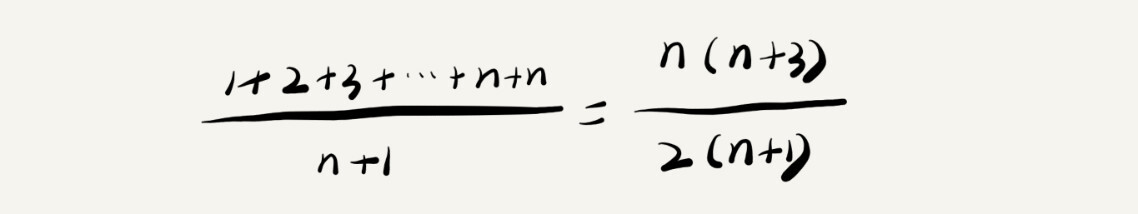
根据时间复杂度标记法,我们可以忽略掉系数、低阶、常量,所以,简化之后得到的平均时间复杂度就是O(n)。
但是我们知道,要查找的变量x,要么在数组里,要么不在数组里,这两种情况的概率都为1/2。另外,在0-(n-1)这个n个位置的概率是1/n。所以,根据概率乘法法则,要查找的数据出现在0-(n-2)中任意位置的概率就是1/(2n)
所以,前面推导过程中存在的最大问题是,没有将各种情况发生的概率都考虑进去。如果都考虑进去,平均时间复杂度的计算过程就会变成这样: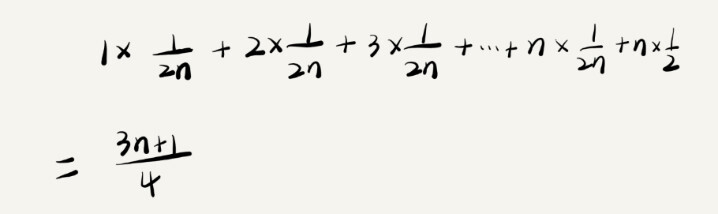
这个值就是概率论中的加权平均值,也叫期望值,所以平均时间复杂度的全称也叫加权平均时间复杂度或者期望时间复杂度
当我们去掉系数和常量后,这段代码的加权平均时间复杂度仍然是O(n)
实际上,大多数情况下我们并不需要区分最好、最坏、平均情况时间复杂度三种情况。很多时候,我们使用一个复杂度就可以满足需求了。只有同一块代码在不同情况下,时间复杂度有量级的差距,我们才会使用这三种复杂度表示法来区分。
均摊时间复杂度
均摊时间复杂度,听起来跟平均时间复杂度有点像,对于初学者来说,这两个概念确实非常容易混淆。其实大部分情况下,我们并不需要区分最好、最坏、平均三种复杂度。平均复杂度只在某些特殊情况下才会用到,而均摊时间复杂度应用的场景更加特殊、更加有限。
// array表示一个长度为n的数组
// 代码中的array.length就等于n
int[] array = new int[n];
int count = 0;
void insert(int val) {
if (count == array.length) {
int sum = 0;
for (int i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}这段代码实现了一个往数组中插入数据的功能。当数组满了,即count == array.length的时候,我们对数组内的所有元素求和,然后清空数组,讲求和的数组插入到数组的第一个位置,然后再插入新的数据。但如果数组一开始就有空闲空间,则直接将数据插入到数组。
这段代码的时间复杂度是多少呢?我们先用前面讲到的三种时间复杂度来分析一下
最理想的状态下,数组中有空闲空间,可以直接进行数据插入,所以最好时间复杂度是O(1)。最坏的情况下,数组没有空闲空间,我们要先做一遍数组遍历求和再插入数据,所以最坏时间复杂度是O(n)。
平均时间复杂度是O(1)。我们来分析一下:数组长度为n,在数组有空闲空间的情况下,每种情况的时间复杂度都为O(1),在数组没有空闲空间的情况下,时间复杂度为O(n)。这n+1种情况发生的概率都一样,都是1/(n+1)。所以,根据加权平均的计算方法,我们求得的平均时间复杂度是:
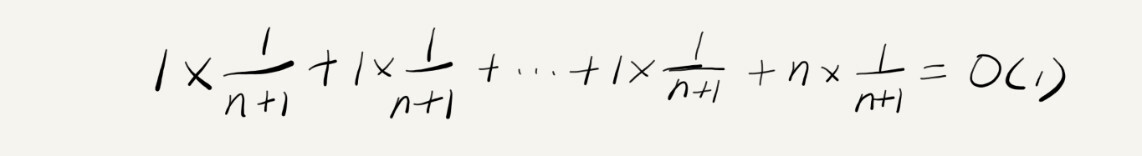
至此,三种复杂度分析完了。但是这个例子里的平均时间复杂度分析其实并不需要那么复杂,不需要引入概率论知识。我们先来对比一下这个insert()和find()。
首先,find()在极端情况下复杂度才为O(1),而insert()在大部分情况下都为O(1),只有在个别情况下为O(n)。这是第一个区别。
第二个区别,对于insert()来说,O(1)时间复杂度的插入和O(n)时间复杂度的插入,出现的频率是非常有规律的,而且有一定的前后时序关系,一般都是一个O(n)插入之后,紧跟着n-1个O(1)插入,循环往复。
所以,针对这种特殊场景的复杂度分析,我们不需要再根据之前的平均复杂度那样分析了,这里韵如一种更加简单的分析方法:摊还分析法,通过摊还分析得到的时间复杂度我们起了一个名字,叫均摊时间复杂度。
在insert()中,每一次O(n)的插入操作,都会跟着n-1次O(1)的插入操作,所以把耗时多的那次操作均摊到接下来的n-1次耗时少的操作上,均摊下来,这一组连续的操作的均摊时间复杂度就是O(1)。这就是均摊分析的大致思路。
均摊时间复杂度和摊还分析应用场景比较特殊,所以我们并不会经常用到。
对一个数据结构进行一组连续的操作时,大部分情况下的时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作都存在前后连贯的时序关系,这个时候我们可以将这一组操作放在一块儿分析,看是否能将最高时间复杂度那次操作的耗时,均摊到其他时间复杂度比较低的操作上。而且,在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况复杂度。


